What they measured (and how)
SoftBank ran its new Transformer model for uplink channel interpolation on GPUs in an over-the-air (OTA) 5G system compliant with 3GPP, then compared against (a) a conventional non-AI baseline and (b) its previous CNN approach. Results and processing timing were captured under real-time constraints.
Key data points
| Metric | Result |
| Uplink throughput vs. non-AI baseline | ≈ +30% |
| Uplink throughput vs. SoftBank’s prior CNN | ≈ +8% |
| End-to-end AI processing time | ≈ 338 μs average (requirement: <1 ms) |
| Downlink throughput (simulation, SRS prediction) at 80 km/h | up to ≈ +29% vs. prior MLP (~+13%) |
| Downlink throughput (simulation, SRS prediction) at 40 km/h | up to ≈ +31% |
Why these tasks?
- Channel interpolation estimates the full channel from sparse pilots; better estimates lead to higher UL rates, especially under interference.
- SRS prediction helps sustain beamforming quality between sounding intervals, which matters as device counts rise and intervals stretch.

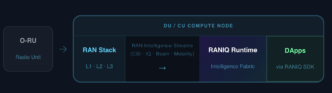
What’s new in the model
SoftBank’s architecture leans on three technical choices:
- Self-attention to capture wide time–frequency correlations that CNNs miss;
- No input normalization (preserving raw amplitudes) to retain physically meaningful information for tasks like channel estimation;
- Unified head that swaps output layers to serve multiple PHY/MAC tasks (interpolation/estimation, SRS prediction, demodulation).

CNN receptive field vs. Transformer self-attention in OFDM grid
From concept to field: AI-RAN’s practical step
The team showed real-time OTA execution on GPUs with sub-millisecond latency, a bar often cited as the gating constraint for PHY/MAC AI in commercial RAN. SoftBank also argues that GPU-centric AI-RAN enables post-deployment model upgrades via software, potentially improving capex efficiency as models evolve.
This follows SoftBank’s March 2025 disclosures that validated three AI-for-RAN use cases—uplink channel interpolation (+20% UL in lab), SRS prediction (**+13% DL** at 80 km/h), and AI-assisted MAC scheduling (~+8% avg.)—developed with NVIDIA (ARC-OTA testbed) and Fujitsu.
Testbed note: NVIDIA’s ARC-OTA is a full-stack, real-time OTA platform built on Aerial CUDA-accelerated L1 (Hopper GPU) and OAI L2 (Grace CPU), designed explicitly for AI-RAN research and over-the-air model trials.
Context: SoftBank’s wider “beyond 5G” push
- 6G spectrum exploration: July 2025 outdoor trials with Nokia at 7 GHz (centimeter-wave) mark Japan’s first reported operator trial of this band.
- Sub-THz mobility: 2024 field tests showed terahertz links supporting connected-car scenarios, broadening THz use beyond FWA/NFC.
- Ecosystem posture: SoftBank is a founding member of the AI-RAN Alliance, which has expanded from its 2024 launch to ~75+ members by early 2025.

Outdoor trial node (7 GHz) in Tokyo streetscape]
Business takeaways (signal, not sizzle)
- Performance at the right layer: A ~30% UL lift at 338 μs processing time is notable because UL is increasingly stressed by cloud/video creation and AI traffic patterns; gains are harder here than on DL.
- Upgrade path: If GPU DU/CU pools can host multiple PHY/MAC AI tasks with a shared backbone, software-only refresh cycles may amortize hardware over more model generations. Vendor roadmaps (Aerial, ARC-OTA availability) support this direction.
- Ops economics: SoftBank explicitly links AI-RAN + GPUs to capex efficiency and 5G-Advanced/6G readiness, but operators will still model power costs and site thermal budgets carefully.
Engineering questions to watch
- Generalization & robustness: How does the model behave across bands, mobility profiles, and interference regimes outside the training set?
- Energy per bit: What’s the J/bit delta vs. classic DSP/FPGA chains once batched efficiently on shared accelerators?
- Lifecycle & toolchain: How are datasets curated, validated, and versioned for safe continuous deployment in live RANs?
- Interoperability: Integration with O-RAN split options, vendor stacks, and scheduler co-design remains critical.